Beats简单介绍
Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。Beats系列包括:Filebeat、Metricbeat、Packetbeat、Winlogbeat、Auditbeat、Heartbeat。每款开源 Beat 都以 libbeat(转发数据时所用的通用库)为基石。以下介绍以Filebeat为例。
filebeat
Filebeat 是使用 Golang 实现的轻量型日志采集器,也是 Elasticsearch stack 里面的一员。本质上是一个 agent ,可以安装在各个节点上,根据配置读取对应位置的日志,并上报到相应的地方去。
Filebeat 的可靠性很强,可以保证日志 At least once 的上报,同时也考虑了日志搜集中的各类问题,例如日志断点续读、文件名更改、日志 Truncated 等。
Filebeat 并不依赖于 ElasticSearch,可以单独存在。我们可以单独使用Filebeat进行日志的上报和搜集。filebeat 内置了常用的 Output 组件, 例如 kafka、ElasticSearch、redis 等,出于调试考虑,也可以输出到 console 和 file 。我们可以利用现有的 Output 组件,将日志进行上报。
当然,我们也可以自定义 Output 组件,让 Filebeat 将日志转发到我们想要的地方。
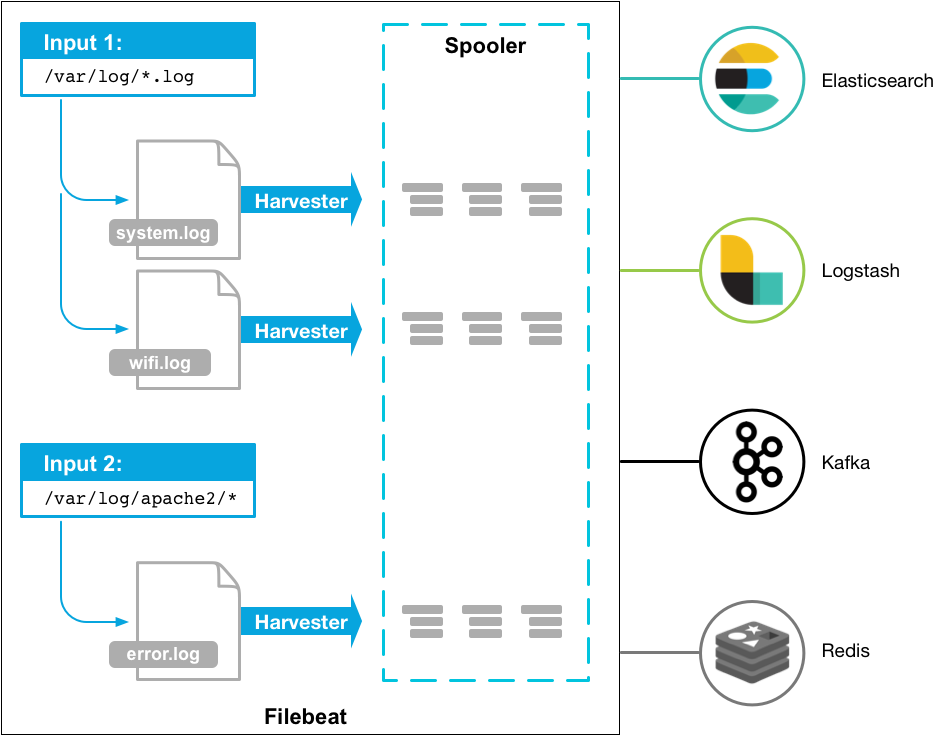
Filebeat 由两个主要组件组成:harvester 和 prospector。
采集器 harvester 的主要职责是读取单个文件的内容。读取每个文件,并将内容发送到 the output。 每个文件启动一个 harvester,harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态。如果文件在读取时被删除或重命名,Filebeat 将继续读取文件。
查找器 prospector 的主要职责是管理 harvester 并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个 harvester。每个 prospector 都在自己的 Go 协程中运行。
注:Filebeat prospector只能读取本地文件, 没有功能可以连接到远程主机来读取存储的文件或日志。
由以上两个组件一起工作来读取文件(tail file)并将事件数据发送到您指定的输出。
其工作流程如下:当启动 Filebeat 程序时,它会启动一个或多个查找器去检测指定的日志目录或文件。对于查找器 prospector 所在的每个日志文件,FIlebeat 会启动收集进程 harvester。 每个 harvester 都会为新内容读取单个日志文件,并将新日志数据发送到后台处理程序,后台处理程序会集合这些事件,最后发送集合的数据到 output 指定的目的地。
除了图中提到的各个组件,整个 filebeat 主要包含以下重要组件:
Crawler:负责管理和启动各个 Input filebeat/beater/crawler.go 有一个startInput方法。filebeat的run读取配置,调用crawler,启动配置里的input,并配置reload时间
Input:负责管理和解析输入源的信息,以及为每个文件启动 Harvester。可由配置文件指定输入源信息。 每个input自己启动一条pipeline
Harvester: Harvester 负责读取一个文件的信息。目前有redis和log实现了这个接口
Pipeline: 负责管理缓存、Harvester 的信息写入以及 Output 的消费等,是 Filebeat 最核心的组件。
Output: 输出源,可由配置文件指定输出源信息。
Registrar:管理记录每个文件处理状态,包括偏移量、文件名等信息。当 Filebeat 启动时,会从 Registrar 恢复文件处理状态。(第一个启动的)
Filebeat启动顺序: registrar, publisher, spooler, crawler。退出顺序:反过来,crawler是第一个。
filebeat 的整个生命周期,几个组件共同协作,完成了日志从采集到上报的整个过程。
一些简单的使用(存疑)
fileBeat 原来支持的功能可以参考官方文档 Filebeat overview | Filebeat Reference [8.11] | Elastic
新增一个input
如果你想要基于 Beats 的源码进行二次开发,增加一个新的 input,你需要直接修改源码。到 2021 年为止,Beats 没有提供生成新 input 代码的工具。
在实现新的 input 时,你需要按照 Beats 的内部框架来实现一些接口和方法。具体来说,每个 input 都需要实现
input.Input接口。这个接口包含了一些方法,如Run(启动 input)、Stop(停止 input)和Wait(等待 input 完全停止)。一般来说,要添加新的 input,你需要完成以下步骤:
在
filebeat/input目录下创建一个新的子目录,用于存放新 input 的代码。在新目录下创建一个实现
input.Input接口的 Go 结构体。这个结构体需要包含Run、Stop和Wait方法,以及任何你需要的其他方法。在新目录下创建一个
config结构体,用于存储新 input 的配置选项。在新目录下创建一个
init函数,用于注册新 input。你可以使用input.Register函数进行注册。修改
filebeat/include/list.go文件,将新 input 的导入语句添加到import。在
filebeat.yml文件中添加新 input 的配置选项。在完成以上步骤后,就可以使用新的 input 了。
可以查看 Beats 的源码,参考已有的 input(如
log和stdin)的实现方式。
新增一个processor
如果你想基于 Beats 的源码进行二次开发,增加一个新的 processor,你需要直接修改源码。到 2021 年为止,Beats 没有提供生成新 processor 代码的工具。
在实现新的 processor 时,你需要按照 Beats 的内部框架来实现一些接口和方法。具体来说,每个 processor 都需要实现
processors.Processor接口。这个接口包含一些方法,如Run(对事件运行 processor)和String(返回 processor 的字符串描述)。一般来说,要添加新的 processor,你需要完成以下步骤:
在
libbeat/processors目录下创建一个新的子目录,用于存放新 processor 的代码。在新目录下创建一个实现
processors.Processor接口的 Go 结构体。这个结构体需要包含Run和String方法,以及你需要的其他方法。(可选)在新目录下创建一个
config结构体,用于存储新 processor 的配置选项。在新目录下创建一个
init函数,用于注册新 processor。你可以使用processors.RegisterPlugin函数进行注册。修改
libbeat/cmd/instance/imports_common.go文件,将新processor的导入语句添加到import。在
filebeat.yml文件中添加新 processor的配置选项。在完成以上步骤后,你就可以使用新的 processor 了。
如果你需要更详细的指导,你可以查看 Beats 的源码,参考已有的 processor(如
add_cloud_metadata和add_docker_metadata)的实现方式。
Input和Module的区别
在 Filebeat 中,module 和 input 是两个关键的配置概念,它们分别代表了数据来源的两种不同级别的抽象。
Input:Input 是 Filebeat 中最基本的数据来源定义。它描述了 Filebeat 从哪里读取原始数据。例如,
loginput 从文件系统的日志文件中读取数据,stdininput 从标准输入读取数据。每个 Input 有一组配置选项,这些选项可以用来定义读取数据的具体行为,例如,paths配置项定义了loginput 从哪些文件路径读取数据。Module:Module 是一个更高级别的数据来源抽象。每个 Module 定义了一组预设的配置,这些配置指示 Filebeat 如何从某一特定类型的数据源(例如,Nginx 或 MySQL 服务器)读取和解析数据。一个 Module 可以包含多个 Fileset,每个 Fileset 定义了一组 Input 和(可选的)处理器,这些 Input 和处理器被预配置为能够解析特定类型的日志文件(例如,Nginx 的 access 日志或 error 日志)。
简单来说,你可以把 Input 看作是具体的数据收集方式,而 Module 则是预配置的数据收集和处理策略,它包含了一组针对特定类型的数据来源的 Input 和处理器配置。你可以单独使用 Input,也可以通过使用 Module 来快速开始收集和解析一种特定类型的日志。